As discussed in this blog post, PSC replication primarily involves the vmdird - VMware Directory Service.
This VMware Directory Service provides a multitenant, peer-replicating LDAP directory service that stores authentication, certificate, lookup, and license information. If your domain contains more than one PSC or embedded VC instance, an update of vmdir content in one vmdir instance is propagated to all other instances of vmdir.
All of this vmdir information is stored in a data.mdb file. This data.mdb file and its contents are essentially what are replicated.
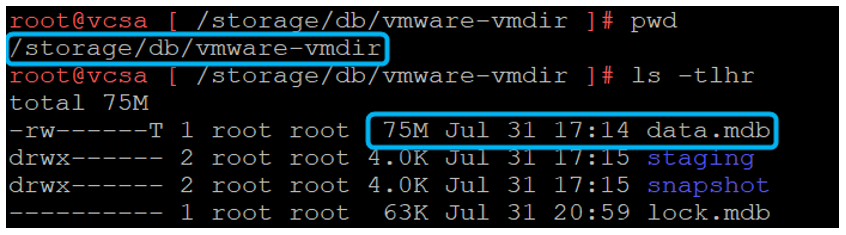
The size of this file is usually about 15-20MB per node – it really should not be beyond 150-200 MB in 99% of the cases.
How Replication is Broken
There are two ways that we see vmdird replication breaking:
Improper snapshots i.e taking snapshots on the PSCs or embedded VCs while they are powered on and therefore actively updating their USNs.
In that state, when we revert a snapshot on either a single node or multiple nodes – that causes a USN mismatch, because the USN that the reverted node sees from its partners is different from what it is expecting. Similarly, the USN that the reverted node is pushing is different from what its partner is expecting – this mismatch causes the VMDIR to go into a read-only or null state.

If the replication cycle, due to either the data.mdb file being too large, or if the network speed is too slow, or a combination of both takes north of 10 seconds – this also causes the VMDIR to go into a read-only or null state.

Right Way to Take PSC/Embedded VC Snapshots
The only safe way to take PSC snapshots is to take them when there is no active vmdird replication.
The safest way to do that is to shutdown all the PSC/embedded VC nodes in the SSO - this way there are no active replication cycles in the SSO.
Once all the nodes are powered off, we can take the snapshots. Once the snapshots are complete, we can power on the nodes again.
That being said, there are instances where it is not possible or feasible to shutdown all the VC nodes in an SSO - especially when we are talking about tight windows where we can take down production, often involving 10+ VC nodes all in the same SSO.
In those situations, we should ATLEAST stop the vmdird service prior to take the snapshot.
So essentially the steps would be, run the following command to stop the vmdird:
service-control --stop vmdirdOnce the service is stopped on all the nodes, take the snapshots. For this scenario, I would recommend taking snapshots with the memory (If we ever have to revert to these snapshots, the vmdird service will still be stopped at the reverted state)
Once the snapshots are complete, start the service across all the nodes:
service-control --start --allWe use the "--start --all" parameters here to start any and all services that might have stopped due to its dependency on the vmdird service.
If we need to revert to a snapshot on a single node (for whatever reason), we have to revert to the same set of snapshots for all the nodes in the SSO – this will preserve replication. Once they are all reverted, we can power on the nodes.
If we just revert a snapshot on just one of the nodes and not all of them, we are back in the same boat of having mismatched USN information - which will break the vmdird replication.