
If you are running a VMware environment with multiple vCenters in Enhanced Linked Mode, then chances are, you have inevitably taken snapshots of vCenters and caused a replication issue due to the vmdir DBs being out of sync. In previous posts, I have talked about how this replication works, and how to not break this replication.
In this post, I will explain the quickest way to repair and recover from a broken replication state and bring all the vCenters back in sync.
VMware GSS has multiple internal scripts and KBs to repair the vmdir DB replication in place. However, there is a publicly accessible utility that also lets us repair the replication. Its called cross-domain repoint.
https://blogs.vmware.com/vsphere/2019/10/repointing-vcenter-server-to-another-sso-domain.html
The primary function of the cross domain repoint, as the name suggests, is to repoint a vCenter node from one SSO domain to another SSO domain (which can be an existing SSO domain or an entirely new one). Due to the nature of this embedded PSC instance, the process of the cross domain repoint involves exporting existing node configuration, completely uninstalling the PSC, and then re-installing the PSC with the destination SSO configuration, and finally re-importing the node configuration.
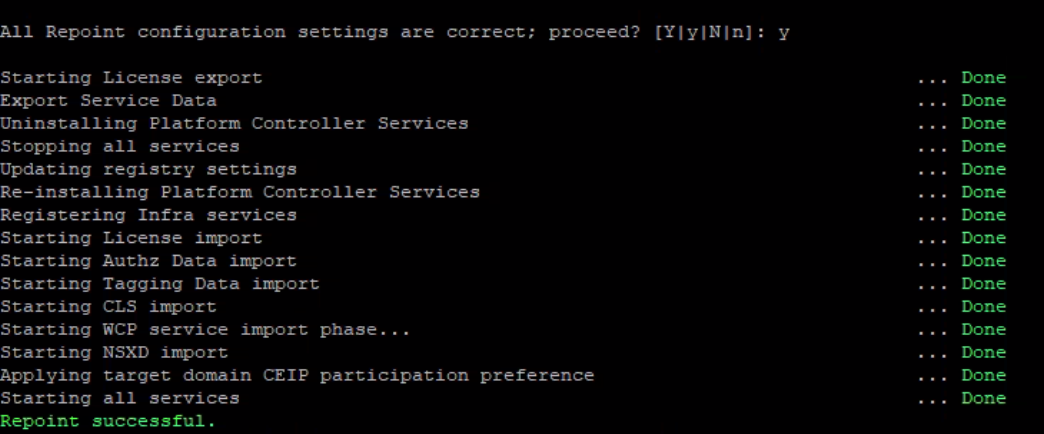
How does a cross repoint help with repairing vmdir replication?
Well, as a part of the cross domain repoint, when the node configuration is exported - it ONLY exports configuration related to the node we are attempting to repoint. It will leave behind any and all information affiliated with its replication partners, their service registration, last USNs etc.
As a result, when it moves to its destination SSO domain, it will bring with itself only its node configuration and then perform a fresh "new" replication cycle with its new replication partners (if they exist)
Using the mechanism above, we can effectively repair any and all broken replication issues, and if needed even split the SSO domain.
Lets explain this further with an example, and lets make it a little complicated:
Say we have 5 vCenters in Enhanced Linked Mode, with replication agreements that look like this:
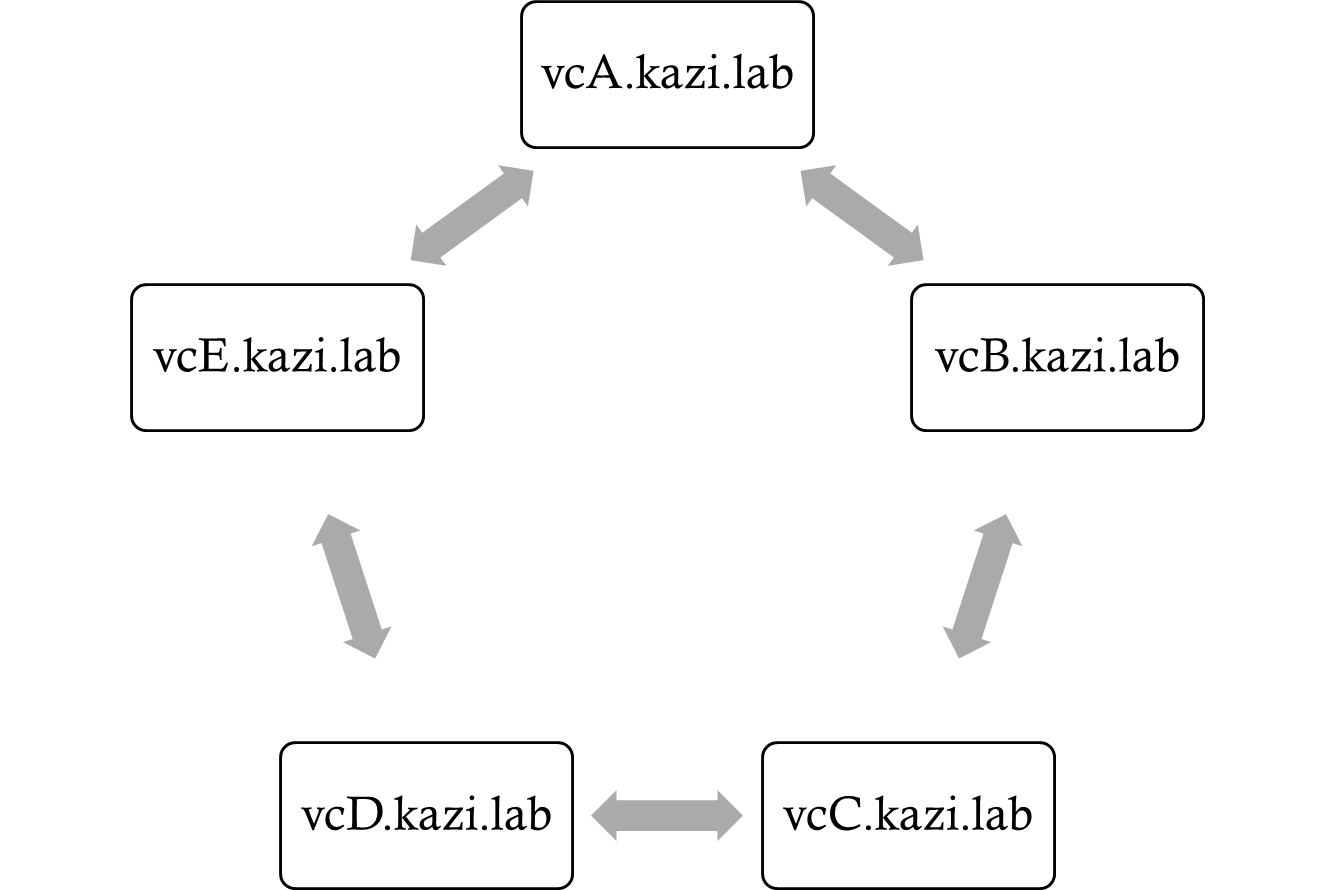
In this replication topology, we notice that we have three broken replication agreements:
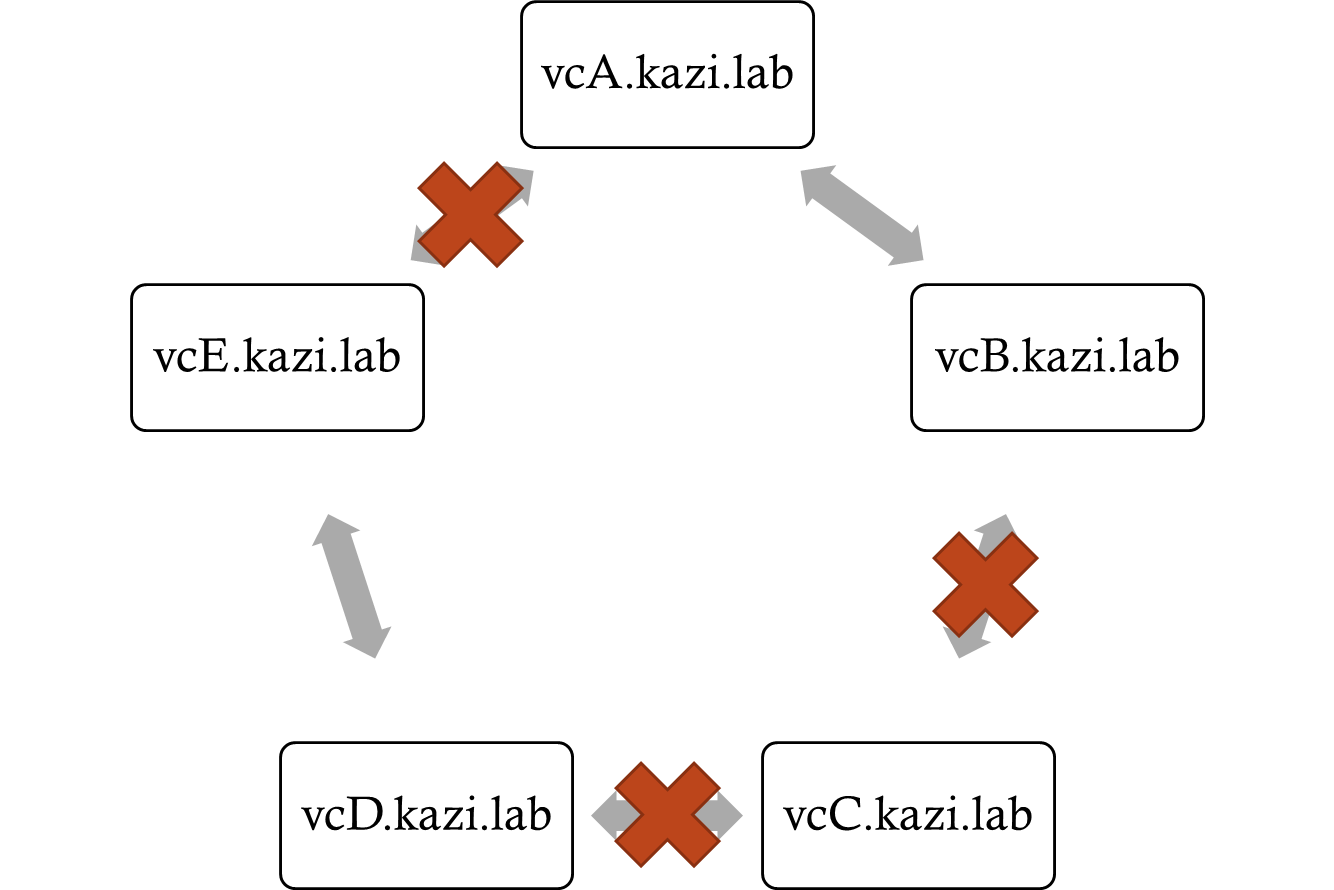
Due to the number of broken replication agreements (due to improper powered on snapshot + restore operations) and the duration that this broken replication has existed, we cannot assume any VC instance to have the best or most accurate vmdir state.
So the best way to recover from this, is to pick a vCenter, domain repoint it to an isolated SSO domain (i.e a new SSO domain) and then domain repoint the other vCenters one-by-one to the new SSO. Like I mentioned above, as each vCenter will only travel to the new SSO with its own node configuration - and then perform a fresh replication cycle - this will allow the vmdir DBs of each vCenter to re-sync.
To break it up into the actual steps that we need to perform:
- Take offline snapshots of all 5 vCenters. We need the offline snapshots because any failure in the cross domain repoint operation is not recoverable. At that point, we have to either rebuild the vCenter or restore it from a backup.
- Pick a vCenter to repoint to an isolated SSO. Lets pick vcA.kazi.lab. SSH into vcA and run the command
cmsso-util domain-repoint -m execute --src-emb-admin Administrator --dest-domain-name vsphere.local - SSH into vcB.kazi.lab, and repoint it to the new SSO:
cmsso-util domain-repoint -m execute --src-emb-admin Administrator --replication-partner-fqdn vcA.kazi.lab --replication-partner-admin Administrator --dest-domain-name vsphere.local - SSH into vcC.kazi.lab, and repoint it to vcB.kazi.lab:
cmsso-util domain-repoint -m execute --src-emb-admin Administrator --replication-partner-fqdn vcB.kazi.lab --replication-partner-admin Administrator --dest-domain-name vsphere.local - SSH into vcD.kazi.lab, and repoint it to vcC.kazi.lab:
cmsso-util domain-repoint -m execute --src-emb-admin Administrator --replication-partner-fqdn vcC.kazi.lab --replication-partner-admin Administrator --dest-domain-name vsphere.local - SSH into vcE.kazi.lab, and repoint it to vcD.kazi.lab:
cmsso-util domain-repoint -m execute --src-emb-admin Administrator --replication-partner-fqdn vcD.kazi.lab --replication-partner-admin Administrator --dest-domain-name vsphere.local - Recreate the replication agreement between vcE and vcA to complete the ring topology:
/usr/lib/vmware-vmdir/bin/vdcrepadmin -f createagreement -2 -h vcA.kazi.lab -H vcE.kazi.lab -u administrator
The same logic applies to any environment with a variable number of replication partners.
While this process is excellent in repairing replication, it does come with some caveats that we need to take into account:
- Do not perform any of the these operations without offline snapshots of all vCenters in the SSO (and ideally a VAMI based backup of all vCenters as well)
- Global Permissions are lost during a domain repoint and will need to be reapplied manually on the destination domain.
- 2nd and 3rd party solutions registered to the source vCenter Server are lost and will need to be re-registered manually after the repoint.
- If you are repointing to a new isolated SSO, there will some permissions missing for the administrator@vsphere.local account, which will need to be re-added manually using the following commands:
ldapmodify -h localhost -D "cn=Administrator,cn=Users,dc=vsphere,dc=local" -W << EOF dn: CN=ComponentManager.Administrators,dc=vsphere,dc=local changetype: modify add: member member: CN=Administrator,CN=Users,dc=vsphere,dc=local EOF ldapmodify -h localhost -D "cn=Administrator,cn=Users,dc=vsphere,dc=local" -W << EOF dn: CN=SystemConfiguration.Administrators,dc=vsphere,dc=local changetype: modify add: member member: CN=Administrators,CN=Builtin,dc=vsphere,dc=local EOF
Note: These commands only need to be run once per domain repoint to an isolated SSO.
So in our example above, we need to run this in an SSH session on vcA.kazi.lab after it has been domain repointed to an isolated SSO, and before proceeding with the next set of domain repoints.
Lastly, I do want to acknowledge that this entire recovery process is .... not simple. There are several things that can go wrong - The domain repoint to an isolated node can fail, the subsequent domain repoints to the new SSO can fail, you may be unsure of the existing replication topology and therefore unsure what node to repoint when and where etc.
If you are in this situation of needing to repair vmdir replication, especially in a production environment - Please reach out to VMware GSS to assist with this, as they will have a lot of internal documentation and resources to triage, troubleshoot and resolve this.
Additional Resources:
https://blogs.vmware.com/vsphere/2019/10/repointing-vcenter-server-to-another-sso-domain.html